http://damoqiongqiu.iteye.com/blog/794468
Web开发者的进化
过去,内存溢出并没有给Web开发者造成太大问题。页面之间的关系保持简单,并且在同一站点的不同地址之间进行导航可以快速地清理任何内存泄漏问题。如果存在泄漏,也小到足以忽略。
新的Web应用需要实践更高的标准。一个页面可能运行数小时,而不会被导航或者通过Web服务端动态刷新信息。通过绑定事件配置、面向对象的Jscript和闭包来创建整个应用,语言特性被推到了一个转折点。通过这些以及其它一些变化,此类内存泄漏模式变得更突出,特别是那些先前被浏览器隐蔽的部分。
好消息是,如果你知道想要找什么,内存泄漏模式可以被简单地发现。你面对的大部分的总所周知的麻烦模式都已经有了应对方法,为了你的利益,仅仅需要少量额外工作。一些页面可能仍然因为小的内存泄漏而性能下降,大部分显而易见的页面可以被简单地删除。
泄漏模式
以下部分将会讨论内存泄漏模式,并且为每种模式指出一些通用的例子。一个极好的模式示例是Jscript的闭包特性,其它一些例子是使用闭包绑定事件。如果你熟悉绑定事件的例子,你就有能力查找并修复大量内存泄漏,但是其它一些与闭包相关的例子可能不那么引人注意。
现在,让我们看看如下模式:
1、循环引用—在IE的COM结构和任何脚本引擎中的对象之间存在交叉引用都会引起内存泄漏。这是最广泛的模式。
2、闭包—闭包是一种特殊的循环引用形式,这是现有Web应用技术中引起泄漏的最大模式。
3、跨页面泄漏—跨页面泄漏通常是,当你从一个站点移动到另一个站点时,由于内部记录对象引起的非常小的泄漏。我们将会检测DOM插入顺序问题,连同一个方法,显示了需要对你的代码进行多么小的变更就可以阻止创建这些记录对象。
4、秀逗模式(假泄漏)—这些不是真的泄漏,但是却非常讨厌,如果你不知道你的内存去了哪里。我们将会检测脚本元素重写操作,当操作必须执行时,它如何表现得像是泄漏了一大块内存。
循环引用
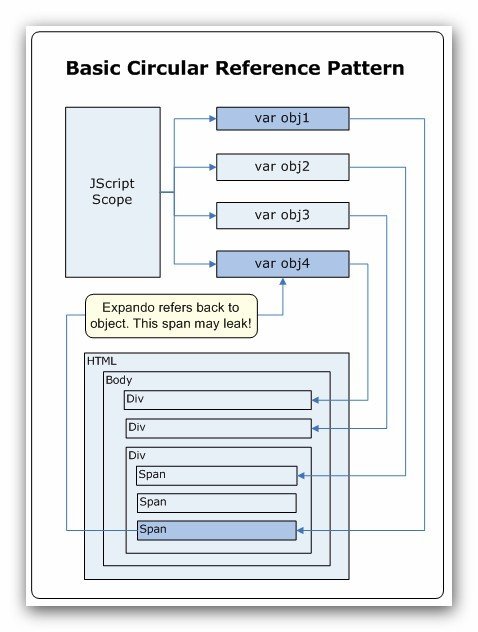
循环引用几乎是所有泄漏的根源。一般来说,脚本引擎通过它们的垃圾收集器处理循环引用,但是一些未知因素会阻止触发它们恰当地工作。在IE中的未知因素是部分脚本访问的一些DOM元素状态。
这个模式引起泄漏的原因是由于COM引用计数。脚本引擎对象(译者注:指obj1)将会持有一个到DOM元素的引用,在清理并释放DOM元素指针之前,会等待所有外部引用被删除。在我们的例子中,我们在脚本引擎中有两个引用:脚本引擎作用域和DOM元素的自定义属性。当终止时,脚本引擎将会释放第一个引用,而DOM元素引用永远不会被释放,因为它在等待脚本引擎对象(译者注:指obj1)释放它!你可能会想,很容易检测这种情况并修正此问题,但是在实际的应用中这种基本情况只不过是冰山一角。你可能在一个有30个对象链条的尾端获得一个循环引用,这种情况很难检测。
如果你想知道这种模式在HTML中看起来是啥样,你可以通过使用一个全局脚本引擎变量和一个DOM元素构造一次内存泄漏,就像如下展示。

- <html>
- <head>
- <script language=”JScript”>
- var myGlobalObject;
- function SetupLeak()
- {
- // 第一步设置脚本域到元素的引用
- myGlobalObject = document.getElementById(“LeakedDiv”);
- // 下一步设置元素到脚本域的引用
- document.getElementById(“LeakedDiv”).expandoProperty = myGlobalObject;
- }
- function BreakLeak()
- {
- document.getElementById(“LeakedDiv”).expandoProperty =
- null;
- }
- </script>
- </head>
- <body onload=”SetupLeak()” onunload=”BreakLeak()”>
- <div id=”LeakedDiv”></div>
- </body>
- </html>
为了打破泄漏模式,你可以显式指定一个null值。通过在document卸载之前指定null值,你就是在告诉脚本引擎,在元素和引擎中的对象之间不再存在任何关联。现在它就可以正确地清理引用并释放DOM元素。这种情况下,你作为Web开发者,对你的对象之间的关系所知道的比脚本引擎更多。
这是基本的模式,指出更复杂的情景比较困难。面向对象的Jscript的一个通常的用法是,通过把它们封装到一个Jscript对象中,从而实现对DOM元素的继承。在构造过程中,你一般传入一个你需要的DOM元素,然后在新建的对象上存储一个到DOM元素的引用,同时在DOM元素上存储一个新建对象引用。使用这种方法,你的应用就可以访问任何所需的东西。问题是,这正是典型的循环引用,但是因为使用了不同的语言形式,它可能不会被注意到。打破这类模式可能会变得更加复杂,你可以使用以上讨论的简单方法。
- <html>
- <head>
- <script language=”JScript”>
- function Encapsulator(element)
- {
- // 设置我们的元素
- this.elementReference = element;
- // 创造我们的循环引用
- element.expandoProperty = this;
- }
- function SetupLeak()
- {
- // 泄漏突然产生
- new Encapsulator(document.getElementById(“LeakedDiv”));
- }
- function BreakLeak()
- {
- document.getElementById(“LeakedDiv”).expandoProperty = null;
- }
- </script>
- </head>
- <body onload=”SetupLeak()” onunload=”BreakLeak()”>
- <div id=”LeakedDiv”></div>
- </body>
- </html>
对此问题更复杂的解决方案涉及注册机制,它被用来标注哪些元素/属性需要被解除挂钩、让元素解除与事件的挂钩,这样它可以在document卸载之前被清理掉,但是你经常又会陷入其它泄漏模式而没有真正解决问题。
闭包
闭包通常需要承担内存泄漏的责任,因为它们会在程序员没有注意到的时候创建循环引用。并不显而易见的是,父函数的参数和局部变量会及时被冻结并持有,直到闭包自身被释放。实际上,这变成了一个常见的编程策略,并且让用户频繁陷入麻烦,对这一点,已经有很多资料可用。因为它们描述了闭包背后的历史细节,连同一些我们需要找出的闭包引起泄漏的特定实例—在把闭包模型应用到我们的循环引用图之后,并且指出了这些额外的引用来自何方。

在普通的循环引用中,有两个固定的对象互相持有对方的引用,但是闭包的情况不同。与直接创建引用不同的是,它们通过从父函数作用域中导入信息而被创建。一般情况下,当调用函数时,一个函数的局部变量和所使用的参数仅仅在函数自身的生命周期中存在。在使用闭包时,这些变量和参数会继续会被外部引用,只要闭包还处于活动状态,既然闭包可以在它们父函数的生命周期之外存活,那么那个函数中的任何变量和参数也可以。在示例中,Parameter 1在函数调用结束之后被正常地释放。因为我们添加了一个闭包,第二个引用被创建,并且第二个引用不会被释放,直到闭包自身被释放掉。如果你恰好把这个闭包绑定到一个事件上,那么你就必须把它从事件上删除。如果你恰好把这个闭包设置到一个自定义属性上,那么你就必须把此自定义属性设置为null。
每次调用都会创建闭包,所以,调用这个函数两次将会创建两个独立的闭包,每个都持用那次所传递进来的参数引用。由于这个显然的特性,闭包非常容易引起泄漏。以下例子提供了使用闭包时引起泄漏的最基本的例子:
- <html>
- <head>
- <script language=”JScript”>
- function AttachEvents(element)
- {
- // 此结构导致element引用ClickEventHandler
- element.attachEvent(“onclick”, ClickEventHandler);
- function ClickEventHandler()
- {
- // 闭包引用了element(译者注:由于element是父函数的局部变量,它会被闭包的作用域引用,这种循环非常隐蔽。)
- }
- }
- function SetupLeak()
- {
- // 泄漏瞬间发生
- AttachEvents(document.getElementById(“LeakedDiv”));
- }
- function BreakLeak()
- {
- }
- </script>
- </head>
- <body onload=”SetupLeak()” onunload=”BreakLeak()”>
- <div id=”LeakedDiv”></div>
- </body>
- </html>
在一篇基础知识文章中,我们实际上建议你不要使用闭包,除非有必要。在这个例子中,我给出了不要在事件处理函数中使用闭包,作为替代,我们可以把闭包移到全局作用域中去。当闭包变成了一个普通函数之后,它不再从它的父函数继承参数和局部变量,所以我们完全不用担心因为闭包引起的循环引用。在没有必要的地方,大部分代码可以通过不使用闭包的机制被修正。
最后,Eric Lippert,脚本引擎的开发者之一,有一篇极好的关于闭包的文章。他的最终忠告也是只有当真的必要时才使用闭包。他的文章没有提到闭包模式的任何解决方法,希望我们在这里已经为你的入门铺垫了足够多的例子。
跨页面泄漏
跨页面泄漏
由于插入顺序问题引起的泄漏几乎总是由于创建中间对象而没有被适当清除而引起的。这就是创建动态元素然后把它们插入到DOM中的这种情况。基本的模式是把两个动态创建的对象临时插入到一起,这将创建一个从子元素到父元素的作用域。之后,当你把这两个元素树插入到主树中时,它们都会继承document作用域,然后临时对象就被泄漏了。以下图表展示了使用两种方法把动态创建的元素插入到树中。在第一种模式中,把每个子元素插入到父元素中,最终把整个子树插入到主树中。如果其它条件相同,这种方法会因为临时对象导致泄漏。在第二种模式中,我们从最顶层开始动态创建元素,一直向下遍历所有孩子,将元素插入到主树中。因为每个插入的节点都继承了主document的作用域,我们从未产生过临时对象。这种方法对于避免潜在的内存泄漏更有效。
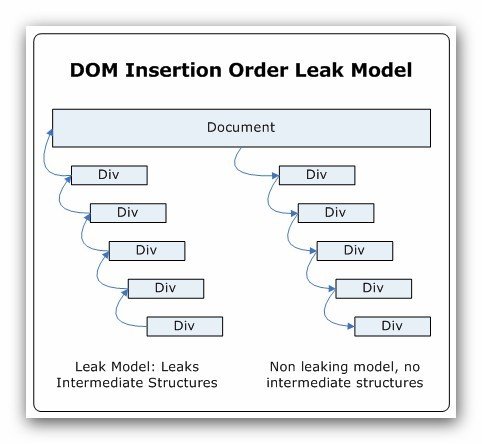
下一步,我们打算铺垫一个大多泄漏检测算法常用的例子。因为我们没有泄漏任何公开可见的元素,并且我们泄漏的对象非常小,你可能从来没有注意到这个问题。为了例子能工作,动态创建的元素必须包含一个脚本指针,形式为一个内嵌的函数。这将允许我们泄漏一个内部脚本对象,当我们把元素插入到一起时它被临时创建。因为泄漏很小,我们必须运行上千个实例。事实上,泄漏的对象只有几个字节。通过运行示例并导航到一个空页面,你可以查看两个版本之间内存使用量的不同。当我们使用第一个DOM模型把子节点插入到父节点、然后把父节点插入到主树中时,我们的内存使用量上升了一点。这是一个导航泄漏,并且内存不会被回收,直到你重启IE进程。如果你多次运行示例,使用第二种DOM模型,先把父节点插入到主树中,然后再把子节点插入到父节点中,你的内存不会持续攀升,你会发现你已经修正了跨页导航泄漏。
- <html>
- <head>
- <script language=”JScript”>
- function LeakMemory()
- {
- var hostElement = document.getElementById(“hostElement”);
- //多运行几次,观察任务管理器中的内存反应
- for(i = 0; i < 5000; i++)
- {
- var parentDiv = document.createElement(“<div onClick=’foo()’>”);
- var childDiv = document.createElement(“<div onClick=’foo()’>”);
- // 这将泄漏一个临时对象
- parentDiv.appendChild(childDiv);
- hostElement.appendChild(parentDiv);
- hostElement.removeChild(parentDiv);
- parentDiv.removeChild(childDiv);
- parentDiv = null;
- childDiv = null;
- }
- hostElement = null;
- }
- function CleanMemory()
- {
- var hostElement = document.getElementById(“hostElement”);
- //多运行几次,观察任务管理器中的内存反应
- for(i = 0; i < 5000; i++)
- {
- var parentDiv = document.createElement(“<div onClick=’foo()’>”);
- var childDiv = document.createElement(“<div onClick=’foo()’>”);
- //改变次序很重要,这不会泄漏
- hostElement.appendChild(parentDiv);
- parentDiv.appendChild(childDiv);
- hostElement.removeChild(parentDiv);
- parentDiv.removeChild(childDiv);
- parentDiv = null;
- childDiv = null;
- }
- hostElement = null;
- }
- </script>
- </head>
- <body>
- <button onclick=”LeakMemory()”>Memory Leaking Insert</button>
- <button onclick=”CleanMemory()”>Clean Insert</button>
- <div id=”hostElement”></div>
- </body>
- </html>
这种泄漏需要澄清,因为我们的方法与IE中的最佳方法相反。理解泄漏的关键点是使用脚本创建的元素已经被插入了。事实上,这对于泄漏至关紧要,因为如果我们创建不含有任何脚本的DOM元素,并且我们同样把它们插入到一起,我们并不会引起内存泄漏问题。这就产生了第二个变通方法,对于更大的子树来说可能更好(在示例中我们仅有两个元素,所以在主DOM之外构建树并不会过多影响性能)。第二种方法将会创建你的元素而不在初始化时插入脚本,这样你就可以安全地构建你的子树。在你把你的子树插入到主DOM中之后, 回过头来再为此节点设置脚本事件。记得遵守循环引用和闭包的原则,这样你就不会在你挂钩事件的代码中导致一个不同的泄漏。
我非常想指出这个问题,因为它显示了不是所有的内存泄漏都能轻松地找出来。在一个小的模式变得可观测之前可能需要经历上千次迭代,并且可能是非常小的一件事,就像插入DOM元素的顺序导致问题显现一样。如果你注意使用最佳编程方法,然后你觉得你是安全的,但是这个泄漏的例子显示出即使是最佳方法也会导致泄漏。我们这里的解决方案是改进最佳方法,甚至介绍了一种新的最佳方法,用来去除泄漏的情况。
秀逗模式(假泄漏)
很多时候,某些API的实际表现和期望的表现可能会导致你误判内存泄漏。假泄漏几乎总是出现在同一个页面的动态脚本操作中,并且在从一个页面导航到一个空页面之后变得很少可观察到。这就是你如何消除跨页面泄漏问题的方法,然后开始观察内存用量是否符合预期。我们将会用使用脚本文本重写作为秀逗模式的例子。
和DOM插入顺序问题一样,此问题也依赖创建临时对象而泄漏内存。通过一次又一次地重写一个脚本元素中的脚本文本,慢慢地你开始泄漏大量脚本引擎对象,它们是被插入在原先的内容中的。特别地,与调试脚本相关的对象会被抛弃,就像完全形成的脚本元素。
- <html>
- <head>
- <script language=”JScript”>
- function LeakMemory()
- {
- //多做几次,查看任务管理器中的内存反应
- for(i = 0; i < 5000; i++)
- {
- hostElement.text = “function foo() { }”;
- }
- }
- </script>
- </head>
- <body>
- <button onclick=”LeakMemory()”>Memory Leaking Insert</button>
- <script id=”hostElement”>function foo() { }</script>
- </body>
- </html>
如果你运行以上代码并再次使用任务管理器技巧,当在“泄漏页面”和空白页面进行导航时,你不会注意到脚本泄漏。这种脚本泄漏完全处于一个页面中,并且当你导航出去时你又会拿回你的内存。这个例子之所以有毛病的原因是由于期望的行为。你期望在重写一些脚本之后原先的脚本不会保留下来。但实际上它保留下来了,因为它可能已经用来绑定事件,并且可能存在外部引用计数。像你能看到的一样,这是一种秀逗模式。表面上看,内存使用量看起来非常糟糕,但是却有一个完全正确的理由。
结论
每一个Web开发者都创建了一个个人的代码案例列表,当他们在代码中看到它们的时候,他们知道存在泄漏并且设法绕过这些泄漏。这非常方便,并且也是如今的Web相对无泄漏的原因。按照模式的方法考虑泄漏,替代代码案例,你可以开始发展更好的战略来处理它们。方法是在设计阶段就把它们考虑进来,并且确定你有对付任何潜在泄漏的计划。使用防御式编码技巧,并且假定你必须清理你自己的所有内存。虽然这是对此问题的夸大,你很少必须清理自己的内存;哪些变量和自定义属性存在潜在泄漏就变得显而易见。
对于模式和设计有兴趣者,我强烈推荐Scott’s short blog entry ,这里示范了删除所有基于闭包的内存泄漏的通用示例。它确实需要更多代码,但是行之有效,并且改进的模式更容易在代码中发现并调试。类似的注册表也可以用来解决基于自定义属性的循环引用,只要注意注册方法自身不会出现泄漏的漏洞(特别是那些使用闭包的地方)!
关于作者
Justin Rogers最近以Object Model开发者的身份加入了IE团队,参与扩展应用。他先前参与一些著名的项目,例如.NET QuickStart Tutorials, .NET Terrarium, 和SQL Server 2005中的 SQL Reporting Services Management Studio。