以下以 IE 代替 Internet Explorer,以 MF 代替 Mozzila Firefox
1. document.form.item 问题
(1)现有问题:
现有代码中存在许多 document.formName.item(“itemName”) 这样的语句,不能在 MF 下运行
(2)解决方法:
改用 document.formName.elements[“elementName”]
(3)其它
参见 2
2. 集合类对象问题
(1)现有问题:
现有代码中许多集合类对象取用时使用 (),IE 能接受,MF 不能。
(2)解决方法:
改用 [] 作为下标运算。如:document.forms(“formName”) 改为 document.forms[“formName”]。
又如:document.getElementsByName(“inputName”)(1) 改为 document.getElementsByName(“inputName”)[1]
(3)其它
3. window.event
(1)现有问题:
使用 window.event 无法在 MF 上运行
(2)解决方法:
MF 的 event 只能在事件发生的现场使用,此问题暂无法解决。可以这样变通:
原代码(可在IE中运行):
<input type=”button” name=”someButton” value=”提交” onclick=”javascript:gotoSubmit()”/>
…
<script language=”javascript”>
function gotoSubmit() {
…
alert(window.event); // use window.event
…
}
</script>
新代码(可在IE和MF中运行):
<input type=”button” name=”someButton” value=”提交” onclick=”javascript:gotoSubmit(event)”/>
…
<script language=”javascript”>
function gotoSubmit(evt) {
evt = evt ? evt : (window.event ? window.event : null);
…
alert(evt); // use evt
…
}
</script>
此外,如果新代码中第一行不改,与老代码一样的话(即 gotoSubmit 调用没有给参数),则仍然只能在IE中运行,但不会出错。所以,这种方案 tpl 部分仍与老代码兼容。
4. HTML 对象的 id 作为对象名的问题
(1)现有问题
在 IE 中,HTML 对象的 ID 可以作为 document 的下属对象变量名直接使用。在 MF 中不能。
(2)解决方法
用 getElementById(“idName”) 代替 idName 作为对象变量使用。
5. 用idName字符串取得对象的问题
(1)现有问题
在IE中,利用 eval(idName) 可以取得 id 为 idName 的 HTML 对象,在MF 中不能。
(2)解决方法
用 getElementById(idName) 代替 eval(idName)。
6. 变量名与某 HTML 对象 id 相同的问题
(1)现有问题
在 MF 中,因为对象 id 不作为 HTML 对象的名称,所以可以使用与 HTML 对象 id 相同的变量名,IE 中不能。
(2)解决方法
在声明变量时,一律加上 var ,以避免歧义,这样在 IE 中亦可正常运行。
此外,最好不要取与 HTML 对象 id 相同的变量名,以减少错误。
(3)其它
参见 问题4
7. event.x 与 event.y 问题
(1)现有问题
在IE 中,event 对象有 x, y 属性,MF中没有。
(2)解决方法
在MF中,与event.x 等效的是 event.pageX。但event.pageX IE中没有。
故采用 event.clientX 代替 event.x。在IE 中也有这个变量。
event.clientX 与 event.pageX 有微妙的差别(当整个页面有滚动条的时候),不过大多数时候是等效的。
如果要完全一样,可以稍麻烦些:
mX = event.x ? event.x : event.pageX;
然后用 mX 代替 event.x
(3)其它
event.layerX 在 IE 与 MF 中都有,具体意义有无差别尚未试验。
8. 关于frame
(1)现有问题
在 IE中 可以用window.testFrame取得该frame,mf中不行
(2)解决方法
在frame的使用方面mf和ie的最主要的区别是:
如果在frame标签中书写了以下属性:
<frame src=”xx.htm” id=”frameId” name=”frameName” />
那么ie可以通过id或者name访问这个frame对应的window对象
而mf只可以通过name来访问这个frame对应的window对象
例如如果上述frame标签写在最上层的window里面的htm里面,那么可以这样访问
ie: window.top.frameId或者window.top.frameName来访问这个window对象
mf: 只能这样window.top.frameName来访问这个window对象
另外,在mf和ie中都可以使用window.top.document.getElementById(“frameId”)来访问frame标签
并且可以通过window.top.document.getElementById(“testFrame”).src = ‘xx.htm’来切换frame的内容
也都可以通过window.top.frameName.location = ‘xx.htm’来切换frame的内容
关于frame和window的描述可以参见bbs的‘window与frame’文章
以及/test/js/test_frame/目录下面的测试
—-adun 2004.12.09修改
9. 在mf中,自己定义的属性必须getAttribute()取得
10.在mf中没有 parentElement parement.children 而用
parentNode parentNode.childNodes
childNodes的下标的含义在IE和MF中不同,MF使用DOM规范,childNodes中会插入空白文本节点。
一般可以通过node.getElementsByTagName()来回避这个问题。
当html中节点缺失时,IE和MF对parentNode的解释不同,例如
<form>
<table>
<input/>
</table>
</form>
MF中input.parentNode的值为form, 而IE中input.parentNode的值为空节点
MF中节点没有removeNode方法,必须使用如下方法 node.parentNode.removeChild(node)
11.const 问题
(1)现有问题:
在 IE 中不能使用 const 关键字。如 const constVar = 32; 在IE中这是语法错误。
(2)解决方法:
不使用 const ,以 var 代替。
12. body 对象
MF的body在body标签没有被浏览器完全读入之前就存在,而IE则必须在body完全被读入之后才存在
13. url encoding
在js中如果书写url就直接写&不要写&例如var url = ‘xx.jsp?objectName=xx&objectEvent=xxx’;
frm.action = url那么很有可能url不会被正常显示以至于参数没有正确的传到服务器
一般会服务器报错参数没有找到
当然如果是在tpl中例外,因为tpl中符合xml规范,要求&书写为&
一般MF无法识别js中的&
14. nodeName 和 tagName 问题
(1)现有问题:
在MF中,所有节点均有 nodeName 值,但 textNode 没有 tagName 值。在 IE 中,nodeName 的使用好象
有问题(具体情况没有测试,但我的IE已经死了好几次)。
(2)解决方法:
使用 tagName,但应检测其是否为空。
15. 元素属性
IE下 input.type属性为只读,但是MF下可以修改
16. document.getElementsByName() 和 document.all[name] 的问题
(1)现有问题:
在 IE 中,getElementsByName()、document.all[name] 均不能用来取得 div 元素(是否还有其它不能取的元素还不知道)。
JS对select动态添加options操作[IE&FireFox兼容]
<select id=”ddlResourceType” onchange=”getvalue(this)”>
</select>
动态删除select中的所有options:
document.getElementById(“ddlResourceType”).options.length=0;
动态删除select中的某一项option:
document.getElementById(“ddlResourceType”).options.remove(indx);
动态添加select中的项option:
document.getElementById(“ddlResourceType”).options.add(new Option(text,value));
上面在IE和FireFox都能测试成功,希望以后你可以用上。
其实用标准的DOM操作也可以,就是document.createElement,appendChild,removeChild之类的。
取值方面
function getvalue(obj)
{
var m=obj.options[obj.selectedIndex].value
alert(m);//获取value
var n=obj.options[obj.selectedIndex].text
alert(n);//获取文本
}
18. 网页不会被缓存
<META HTTP-EQUIV=”pragma” CONTENT=”no-cache”>
<META HTTP-EQUIV=”Cache-Control” CONTENT=”no-cache, must-revalidate”>
<META HTTP-EQUIV=”expires” CONTENT=”Wed, 26 Feb 1997 08:21:57 GMT”>
或者<META HTTP-EQUIV=”expires” CONTENT=”0″>
25.在打开的子窗口刷新父窗口的代码里如何写?
window.opener.location.reload()
28. 检查一段字符串是否全由数字组成
<script language=”javascript”><!–
function checkNum(str){return str.match(//D/)==null}
alert(checkNum(“1232142141”
alert(checkNum(“123214214a1″
// –></script>
31.TEXTAREA自适应文字行数的多少
<textarea rows=1 name=s1 cols=27 onpropertychange=”this.style.posHeight=this.scrollHeight”>
</textarea>
33. 选择了哪一个Radio
<HTML><script language=”vbscript”>
function checkme()
for each ob in radio1
if ob.checked then window.alert ob.value
next
end function
</script><BODY>
<INPUT name=”radio1″ type=”radio” value=”style” checked>style
<INPUT name=”radio1″ type=”radio” value=”barcode”>Barcode
<INPUT type=”button” value=”check” onclick=”checkme()”>
</BODY></HTML>
————————————————————————-
注意: concat 、 match 、 replace 和 search 函数是在 JavaScript 1.2 中加入的。所有其它函数在 JavaScript 1.0 就已经提供了。
去掉前后空格:str.replace(/(^\s*)|(\s*$)/g,””)47.
? concat() – 将两个或多个字符的文本组合起来,返回一个新的字符串。
? indexOf() – 返回字符串中一个子串第一处出现的索引。如果没有匹配项,返回 -1 。
? charAT() – 返回指定位置的字符。
? lastIndexOf() – 返回字符串中一个子串最后一处出现的索引,如果没有匹配项,返回 -1 。
? match() – 检查一个字符串是否匹配一个正则表达式。
? substring() – 返回字符串的一个子串。传入参数是起始位置和结束位置。
? replace() – 用来查找匹配一个正则表达式的字符串,然后使用新字符串代替匹配的字符串。
? search() – 执行一个正则表达式匹配查找。如果查找成功,返回字符串中匹配的索引值。否则返回 -1 。
? slice() – 提取字符串的一部分,并返回一个新字符串。
? split() – 通过将字符串划分成子串,将一个字符串做成一个字符串数组。
? length() – 返回字符串的长度,所谓字符串的长度是指其包含的字符的个数。
? toLowerCase() – 将整个字符串转成小写字母。
? toUpperCase() – 将整个字符串转成大写字母。
48, 关于鼠标拖动,改变层大小。──看看微软的做法.
〈script〉
document.execCommand(“2D-position”,false,true);
〈/script〉
〈DIV contentEditable=true〉
〈DIV style=”WIDTH: 300px; POSITION: absolute; HEIGHT: 100px; BACKGROUND-COLOR: red”〉移动层〈/DIV〉
〈/DIV〉
28,自动显示主页最后更新日期.
〈script〉
document.write(“最后更新日期:”+document.lastModified+””)
〈/script〉
38,利用〈IFRAME〉来给网页中插入网页。
经常我看到很多网页中又有一个网页,还以为是用了框架,其实不然,是用了〈IFRAME〉,它只适用于IE,NS可是不支持〈IFRAME〉的,但围着的字句只有在浏览器不支援 iframe 标记时才会显示,如〈noframes〉一样,可以放些提醒字句之类的话。
你注意啊!下面请和我学习它的用法。
分 析代码:〈iframe src=”iframe.html” name=”test” align=”MIDDLE” width=”300″ height=”100″ marginwidth=”1″ marginheight=”1″ frameborder=”1″ scrolling=”Yes”〉 〈/iframe〉
src=”iframe.html”
用来显示〈IFRAME〉中的网页来源,必要加上相对或绝对路径。
name=”test”
这是连结标记的 target 参数所需要的。
align=”MIDDLE”
可选值为 left, right, top, middle, bottom,作用不大 。
width=”300″ height=”100″
框窗的宽及长,以 pixels 为单位。
marginwidth=”1″ marginheight=”1″
该插入的文件与框边所保留的空间。
frameborder=”1″
使用 1 表示显示边框, 0 则不显示。(可以是 yes 或 no)
scrolling=”Yes”
使用 Yes 表示容许卷动(内定), No 则不容许卷动。
29,如何让滚动条出现在左边?
我想居然在论坛中有人发表了这段代码,很有意思,它的确照顾一些左撇子,呵呵!
〈html dir=”rtl”〉
〈body bgcolor=”#000000″ text=”#FFFFFF”〉
〈table height=18 width=212 align=center bgcolor=#FFFFFF dir=”ltr” cellspacing=”1″ cellpadding=”0″〉
〈tr〉
〈td bgcolor=”#FF0000″ 〉是不是你的滚动条在左边啊〈/td〉
〈/tr〉
〈/table〉
〈/body〉
〈/html〉
34,禁止鼠标右键查看网页源代码。
〈SCRIPT language=javascript〉
function click()
{if (event.button==2) {alert(`你好,欢迎光临!`) }}
document.onmousedown=click
〈/SCRIPT〉
补充说明:
鼠标完全被封锁,可以屏蔽鼠标右键和网页文字。
〈 body oncontextmenu=”return false” ondragstart=”return false” onselectstart=”return false”〉
11,如何改变鼠标的形状?
在Dreamweaver4中CSS样式面板:
按CTR +SHIFT+E–出现样式表对话框,点击NEW,出现编辑对话框,在左边最后一项extensions-cursor 选择你要改的指针形式就可以了,然后把你要想改变的地方运用样式表,如果整页都有在〈body bgcolor=”#003063″ text=”#ffffff” id=all〉中加入就行了。
〈span style=”cursor:X`〉样例〈/span〉
这里选择(文本)作为对象,还可以自己改为其他的,如link等。
x 可以等于=hand(手形)、crosshair(十字)、text(文本光标)、wait(顾名思义啦)、default(默认效果)、help(问 号)、e-size(向右箭头)、ne-resize(向右上的箭头)、nw-resize(向左上的箭头)、w-resize(向左的箭头)、sw- resize(左下箭头)、s-resize(向下箭头)、se-resize(向右下箭头)、auto(系统自动给出效果)。

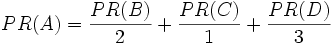
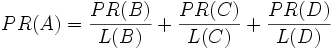




 等于 0
等于 0