

- 项目主页:https://jiupinjia.github.io/rocket-recycling/
- GitHub 地址:https://github.com/jiupinjia/rocket-recycling









作者简介

Uncategorized 分类中有 13 篇文章
作者简介
前阵子工作太忙,好久没做个人项目了,最近久违地想做一个机器人项目玩,设计中需要用到高性能超小体积的伺服电机。
电机这一块性能满足项目需求的基本上只有无刷电机可以选了–又要大功率、大扭矩,又要体积小,成本还最好不要太高,选择低KV值的无刷电机显然是最合适的。我预计的方案中计划把减速器也省略了,采用扭矩无刷电机直驱。那么作为机器人硬件三大核心部件(电机、减速器、驱动器)之一的驱动器,我感觉是有必要自己设计一下的,因此这里把我学习FOC过程中看到的一些有关无刷电机矢量控制的资料和个人理解整理分享出来。
FOC(Field-Oriented Control),直译是磁场定向控制,也被称作矢量控制(VC,Vector Control),是目前无刷直流电机(BLDC)和永磁同步电机(PMSM)高效控制的最优方法之一。FOC旨在通过精确地控制磁场大小与方向,使得电机的运动转矩平稳、噪声小、效率高,并且具有高速的动态响应。
简单来说就是,FOC是一种对无刷电机的驱动控制方法,它可以让我们对无刷电机进行“像素级”控制,实现很多传统电机控制方法所无法达到的效果~
玩过航模的同学可能对无刷电机很熟悉,也应该知道航模中对于无刷电机的驱动使用的是电子调速器(ESC)也就是我们常说的电调,那么这个FOC驱动器和普通的电调有什么区别呢?
 航模中的无刷电调
航模中的无刷电调
FOC的优势:
电调的优势:
综上大家应该可以看出来,FOC驱动器在控制性能上是要比电调强大得多的,其优异的性能和磁场定向控制的原理是密不可分的,下面就会详细介绍FOC控制的实现方法。
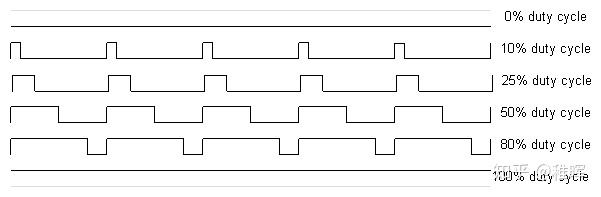 不同占空比的PWM波形
不同占空比的PWM波形
本质是利用面积等效原理来改变波形的有效值。举个例子,一个电灯只有开和关两个状态,那么要怎么让它实现50%亮度的效果的呢?只需要让它在一半时间开,一半时间关,交替执行这两个动作只要频率足够高,在人眼(低通滤波器)看起来就是50%亮度的样子了。而其中高电平占一个开关周期的比例,就叫做占空比。利用PWM可以实现使用离散的开关量来模拟连续的电压值。
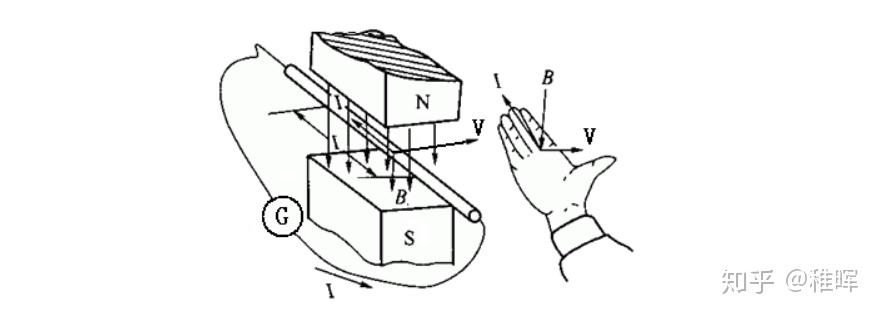
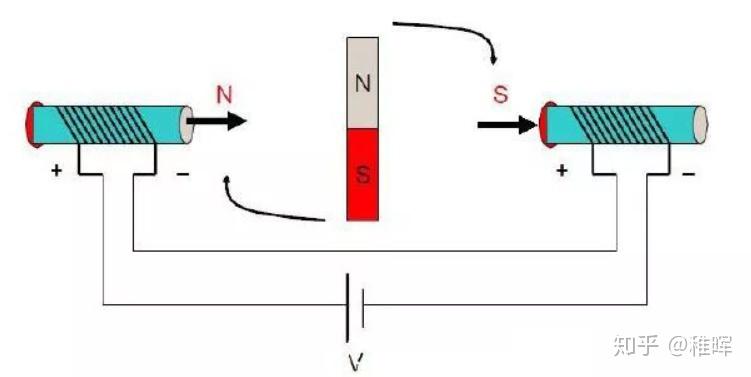
考察下图情况中的直流电机基本模型,根据磁极异性相吸同性相斥的原理,中间永磁体在两侧电磁铁的作用下会被施加一个力矩并发生旋转,这就是电机驱动的基本原理:
对于简化的无刷电机来说,以三相二极内转子电机为例,定子的三相绕组有星形联结方式和三角联结方式,而三相星形联结的二二导通方式最为常用,这里就用该模型来做个简单分析:
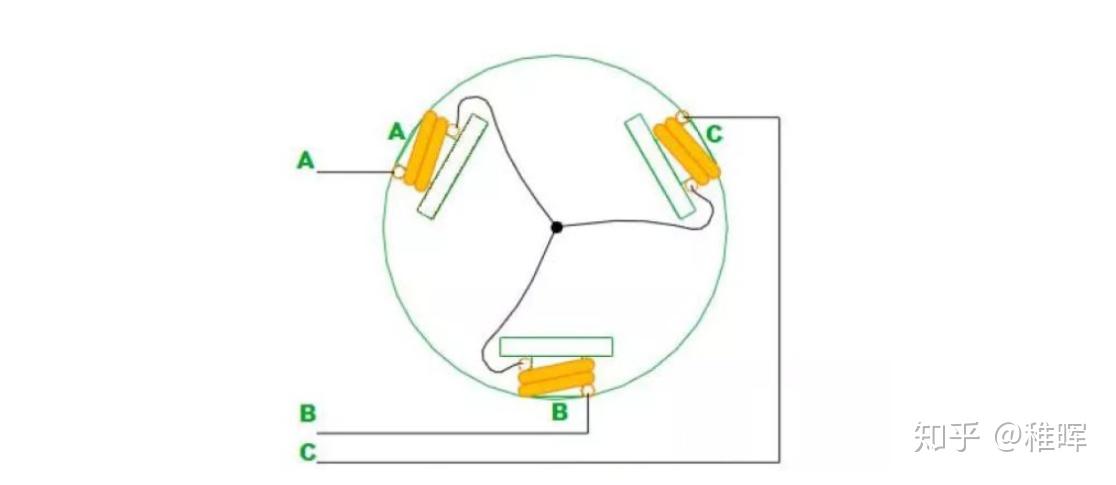
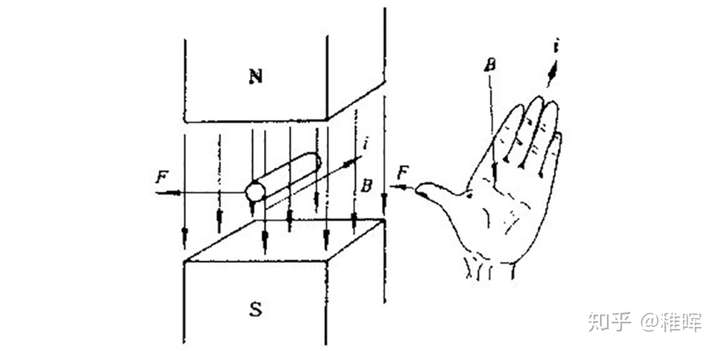
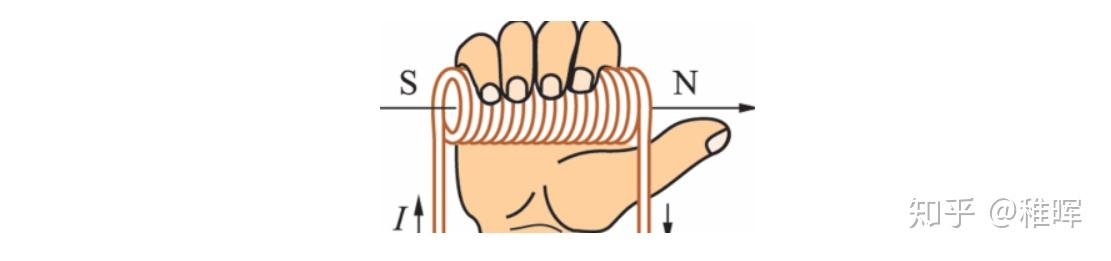
如上图所示,无刷电机三相的连接方式是每一相引出导线的一头,而另一头和其他相两两相连。这个情况下假如我们对A、B极分别施加正电压和负电压,那么由右手螺旋定则可以判断出线圈磁极的方向如下图:
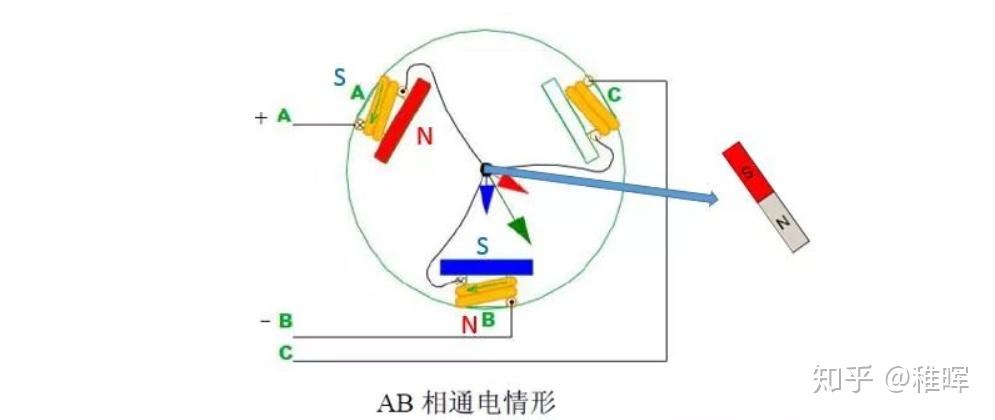
思考一下这时候中间的转子处于什么角度的时候收到的力矩最大呢?
没错就是和CO(O为中心点)连线平行的时候,磁铁会受到A、B两个磁极一推一拉的作用,直到旋转到与AB连线平行的且磁铁内部磁力线方向和AB间磁力线方向一致的时候,受合力矩为0且稳定,也就是上图中右边的状态。换句话说,AB相通电会让转子努力转到上图中右边的状态。至于C这时暂时不起作用。
同理,我们下一阶段换成AC相通电,这时候转子会倾向于转到下图右边水平的角度:
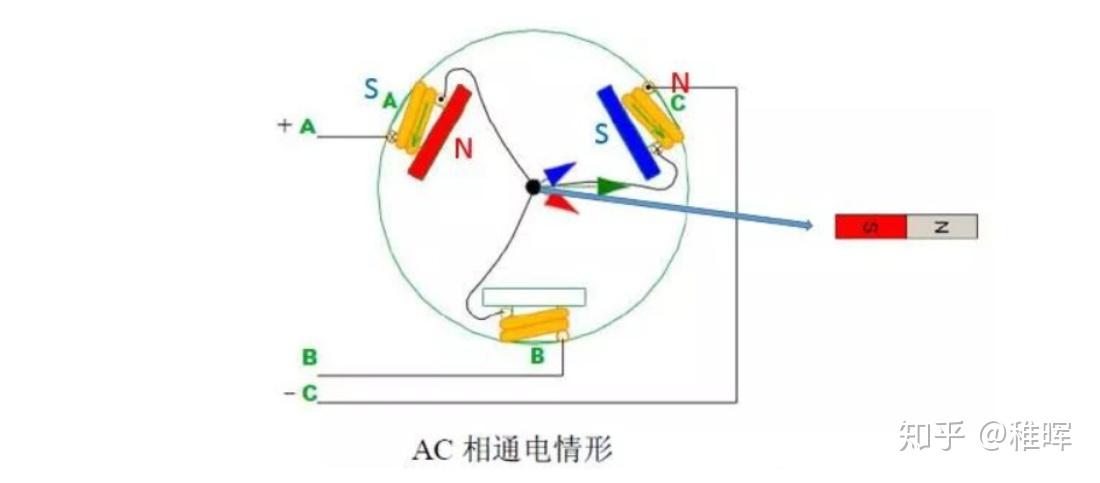
然后BC相通电:
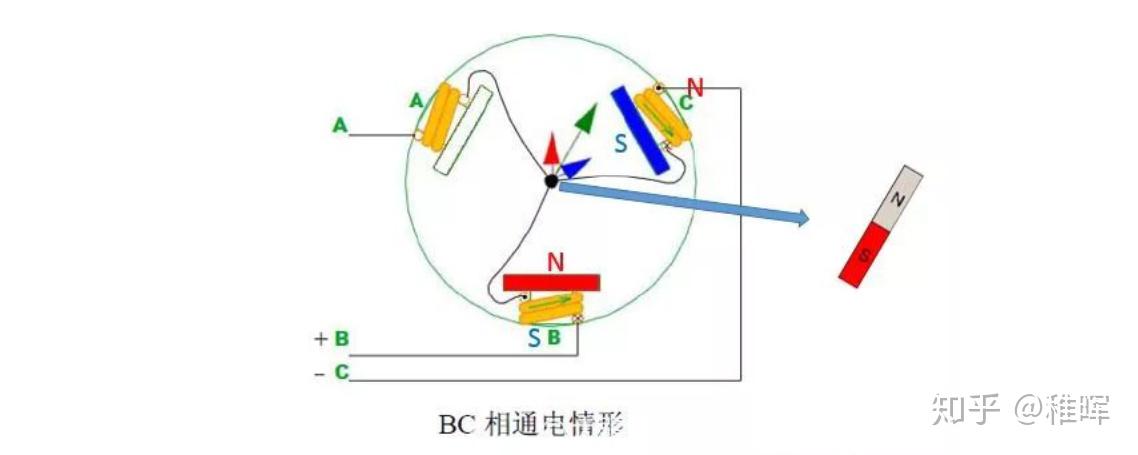
…
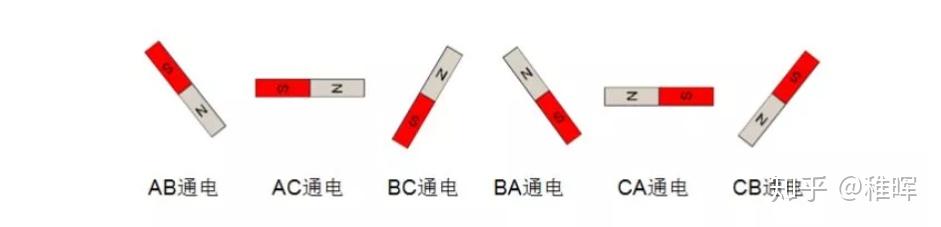
以此类推,可以得到每个通电状态下转子的角度,就是下图中的6个状态,每个状态相隔60度,6个过程即完成了完整的转动,共进行了6次换相:
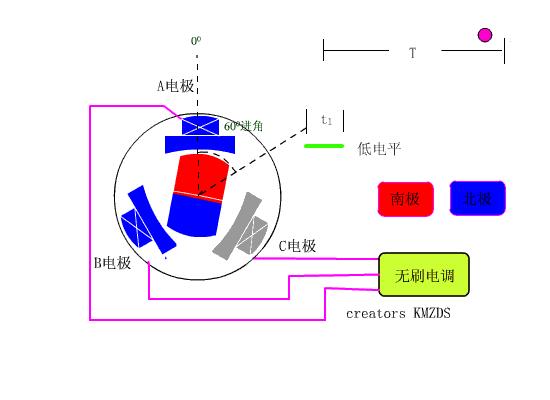
整个过程就好像骑在毛驴上吊一根胡萝卜一样,旋转的磁场牵引着永磁体不断旋转:
而这个换向的操作,就是需要驱动器去完成的。
这也是无刷电机和有刷电机最大的区别,即不像有刷电机的机械换向,无刷电机是通过电子换向来驱动转子不断地转动,而换向的频率则决定了电机的转速。
至于什么时候怎么知道该换到哪个供电相?如何产生更平滑的换向电压?如何提高电源的利用效率?这些都是FOC控制方法要探讨和解决的问题。
无刷电机其实可以分为无刷直流电机(BLDC,我们航模上都是用这种)和永磁同步电机(PMSM),结构大同小异,主要区别在于制造方式(线圈绕组方式)不同导致的一些特性差异(比如反电动势的波形)。
从上面分析的无刷电机模型其实可以看到,由于转子在磁场中只有6个稳定的状态,因此旋转过程其实是不平滑的,存在扭矩的抖动(没有通电的时候可以用手转一下无刷电机,会感受到这种“颗粒感”)。因此为了解决这个问题,从“硬件”和从“软件”出发有两个解决方案,这就衍生出了BLDC和PMSM的区别。
简单地说,BLDC由于反电动势接近梯形波,所以依然是采用方波驱动,肯定是会有上面说的抖动问题的,但是转一圈抖6下太明显了,如果我增加电机槽、极对数(也就是磁铁对数),那以前是360度里面抖6下,现在变成120度里面抖6下,甚至更小,这样“颗粒感”不就变得更小了嘛?实际中买到的BLDC电机基本都是多极对的(比如下图),原理跟之前的分析是一样的,出来的都是三相信号(图中的三根线),可以自己进行类推。

而另一方面,为什么我们非得用方波这种不平滑的波来驱动电机呢,用正弦波它不香吗?是的,这就是PMSM解决问题的方式,由于PMSM的反电动势被设计为正弦波的形状,我们用软件和算法结合PWM技术将方波转变成等效的正弦波,再来驱动电机,结果美滋滋,控制效果很理想。当然为了产生更好的正弦波、更好的旋转磁场,驱动器、控制算法就变得非常复杂,这也是FOC的实现原理,后面会进行详细介绍。
arm-gcc-none-eabi-gcc➜ ~ brew cask install gcc-arm-embedded
==> Satisfying dependencies
==> Downloading https://developer.arm.com/-/media/Files/downloads/gnu-rm/7-2017q4/gcc-arm-none-eabi-7-2017-q4-major-mac.tar.bz2
######################################################################## 100.0%
==> Verifying checksum for Cask gcc-arm-embedded
==> Installing Cask gcc-arm-embedded
==> Linking Binary 'arm-none-eabi-strip' to '/usr/local/bin/arm-none-eabi-strip'.
==> Linking Binary 'arm-none-eabi-ar' to '/usr/local/bin/arm-none-eabi-ar'.
==> Linking Binary 'arm-none-eabi-as' to '/usr/local/bin/arm-none-eabi-as'.
==> Linking Binary 'arm-none-eabi-c++' to '/usr/local/bin/arm-none-eabi-c++'.
==> Linking Binary 'arm-none-eabi-c++filt' to '/usr/local/bin/arm-none-eabi-c++filt'.
==> Linking Binary 'arm-none-eabi-cpp' to '/usr/local/bin/arm-none-eabi-cpp'.
==> Linking Binary 'arm-none-eabi-elfedit' to '/usr/local/bin/arm-none-eabi-elfedit'.
==> Linking Binary 'arm-none-eabi-g++' to '/usr/local/bin/arm-none-eabi-g++'.
==> Linking Binary 'arm-none-eabi-gcc' to '/usr/local/bin/arm-none-eabi-gcc'.
==> Linking Binary 'arm-none-eabi-gcc-ar' to '/usr/local/bin/arm-none-eabi-gcc-ar'.
==> Linking Binary 'arm-none-eabi-gcc-nm' to '/usr/local/bin/arm-none-eabi-gcc-nm'.
==> Linking Binary 'arm-none-eabi-gcc-ranlib' to '/usr/local/bin/arm-none-eabi-gcc-ranlib'.
==> Linking Binary 'arm-none-eabi-gcov' to '/usr/local/bin/arm-none-eabi-gcov'.
==> Linking Binary 'arm-none-eabi-gcov-tool' to '/usr/local/bin/arm-none-eabi-gcov-tool'.
==> Linking Binary 'arm-none-eabi-gdb' to '/usr/local/bin/arm-none-eabi-gdb'.
==> Linking Binary 'arm-none-eabi-gdb-py' to '/usr/local/bin/arm-none-eabi-gdb-py'.
==> Linking Binary 'arm-none-eabi-gprof' to '/usr/local/bin/arm-none-eabi-gprof'.
==> Linking Binary 'arm-none-eabi-ld' to '/usr/local/bin/arm-none-eabi-ld'.
==> Linking Binary 'arm-none-eabi-ld.bfd' to '/usr/local/bin/arm-none-eabi-ld.bfd'.
==> Linking Binary 'arm-none-eabi-nm' to '/usr/local/bin/arm-none-eabi-nm'.
==> Linking Binary 'arm-none-eabi-objcopy' to '/usr/local/bin/arm-none-eabi-objcopy'.
==> Linking Binary 'arm-none-eabi-objdump' to '/usr/local/bin/arm-none-eabi-objdump'.
==> Linking Binary 'arm-none-eabi-ranlib' to '/usr/local/bin/arm-none-eabi-ranlib'.
==> Linking Binary 'arm-none-eabi-readelf' to '/usr/local/bin/arm-none-eabi-readelf'.
==> Linking Binary 'arm-none-eabi-size' to '/usr/local/bin/arm-none-eabi-size'.
==> Linking Binary 'arm-none-eabi-strings' to '/usr/local/bin/arm-none-eabi-strings'.
==> Linking Binary 'arm-none-eabi-addr2line' to '/usr/local/bin/arm-none-eabi-addr2line'.
gcc-arm-embedded was successfully installed!
➜ ~ arm-none-eabi-gcc --version
arm-none-eabi-gcc (GNU Tools for Arm Embedded Processors 7-2017-q4-major) 7.2.1 20170904 (release) [ARM/embedded-7-branch revision 255204]
Copyright (C) 2017 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
➜ ~ which arm-none-eabi-gcc
/usr/local/bin/arm-none-eabi-gcc
How I installed GCC ARM on my Mac 10.9 Mac Book Pro
st-link➜ u-boot-2016.05 brew install stlink
Updating Homebrew...
==> Auto-updated Homebrew!
==> Downloading https://homebrew.bintray.com/bottles/stlink-1.4.0.el_capitan.bottle.tar.gz
######################################################################## 100.0%
==> Pouring stlink-1.4.0.el_capitan.bottle.tar.gz
/usr/local/Cellar/stlink/1.4.0: 27 files, 702KB
➜ u-boot-2016.05 st-info --version
v1.4.0
➜ ~ st-info --flash
0x80000
➜ ~ st-info --version
v1.4.0
➜ ~ st-info --flash
➜ ~ st-info --chipid
0x0433
➜ ~ st-info --serial
303636454646343934393531373835
➜ ~ st-flash
invalid command line
stlinkv1 command line: ./st-flash [--debug] [--reset] [--format <format>] [--flash=<fsize>] {read|write} /dev/sgX <path> <addr> <size>
stlinkv1 command line: ./st-flash [--debug] /dev/sgX erase
stlinkv2 command line: ./st-flash [--debug] [--reset] [--serial <serial>] [--format <format>] [--flash=<fsize>] {read|write} <path> <addr> <size>
stlinkv2 command line: ./st-flash [--debug] [--serial <serial>] erase
stlinkv2 command line: ./st-flash [--debug] [--serial <serial>] reset
Use hex format for addr, <serial> and <size>.
fsize: Use decimal, octal or hex by prefix 0xXXX for hex, optionally followed by k=KB, or m=MB (eg. --flash=128k)
Format may be 'binary' (default) or 'ihex', although <addr> must be specified for binary format only.
./st-flash [--version]
➜ ~ st-flash erase
st-flash 1.4.0
2017-12-31T17:30:22 INFO src/common.c: Loading device parameters....
2017-12-31T17:30:22 INFO src/common.c: Device connected is: F4 device (Dynamic Efficency), id 0x10006433
2017-12-31T17:30:22 INFO src/common.c: SRAM size: 0x18000 bytes (96 KiB), Flash: 0x80000 bytes (512 KiB) in pages of 16384 bytes
Mass erasing......
STM32CubeMX3.1 下载安装 STM32CubeMX 后,New Project新建 NUCLEO-F401RE 工程,选择板子或者芯片型号:

3.2 Boards List中选中的板子,双击打开配置界面,根据 UM1724 文档 的 6.4 小节可以看到,LED2为 PA5。如果之前是选择的板子,那么Cube就已经帮你设定好了;如果选择的时芯片,那么自己标记一下就可以了。

3.2 保存配置,并生成工程和代码


3.3 进入工程所在根目录,make工程,并修复 Cube 的自动生成的一些 Makefile 的错误。
错误一:没有指定 arm-none-eabi-gcc完整路径,提示找不到编译器
➜ 0_blinking make
mkdir build
/arm-none-eabi-gcc -c -mcpu=cortex-m4 -mthumb -mfpu=fpv4-sp-d16 -mfloat-abi=hard -DUSE_HAL_DRIVER -DSTM32F401xE -IInc -IDrivers/STM32F4xx_HAL_Driver/Inc -IDrivers/STM32F4xx_HAL_Driver/Inc/Legacy -IDrivers/CMSIS/Device/ST/STM32F4xx/Include -IDrivers/CMSIS/Include -Og -Wall -fdata-sections -ffunction-sections -g -gdwarf-2 -MMD -MP -MF"build/stm32f4xx_hal_gpio.d" -MT"build/stm32f4xx_hal_gpio.d" -Wa,-a,-ad,-alms=build/stm32f4xx_hal_gpio.lst Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c -o build/stm32f4xx_hal_gpio.o
/bin/sh: /arm-none-eabi-gcc: No such file or directory
make: *** [build/stm32f4xx_hal_gpio.o] Error 127
修复一:添加 BINPATH路径,可以用which arm-none-eabi-gcc 查看确认
#######################################
# binaries
#######################################
BINPATH = /usr/local/bin/
PREFIX = arm-none-eabi-
CC = $(BINPATH)/$(PREFIX)gcc
AS = $(BINPATH)/$(PREFIX)gcc -x assembler-with-cpp
CP = $(BINPATH)/$(PREFIX)objcopy
AR = $(BINPATH)/$(PREFIX)ar
SZ = $(BINPATH)/$(PREFIX)size
HEX = $(CP) -O ihex
BIN = $(CP) -O binary -S
错误二:多次引用源代码,导致链接时重复
➜ 0_blinking make
/usr/local/bin//arm-none-eabi-gcc -c -mcpu=cortex-m4 -mthumb -mfpu=fpv4-sp-d16 -mfloat-abi=hard -DUSE_HAL_DRIVER -DSTM32F401xE -IInc -IDrivers/STM32F4xx_HAL_Driver/Inc -IDrivers/STM32F4xx_HAL_Driver/Inc/Legacy -IDrivers/CMSIS/Device/ST/STM32F4xx/Include -IDrivers/CMSIS/Include -Og -Wall -fdata-sections -ffunction-sections -g -gdwarf-2 -MMD -MP -MF"build/stm32f4xx_hal_gpio.d" -MT"build/stm32f4xx_hal_gpio.d" -Wa,-a,-ad,-alms=build/stm32f4xx_hal_gpio.lst Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c -o build/stm32f4xx_hal_gpio.o
············
build/stm32f4xx_hal_msp.o: In function `HAL_MspInit':
/Users/linjinhui/workplace/stm32f401re/0_blinking/Src/stm32f4xx_hal_msp.c:50: multiple definition of `HAL_MspInit'
build/stm32f4xx_hal_msp.o:/Users/linjinhui/workplace/stm32f401re/0_blinking/Src/stm32f4xx_hal_msp.c:50: first defined here
build/main.o: In function `_Error_Handler':
/Users/linjinhui/workplace/stm32f401re/0_blinking/Src/main.c:222: multiple definition of `_Error_Handler'
build/main.o:/Users/linjinhui/workplace/stm32f401re/0_blinking/Src/main.c:222: first defined here
build/main.o: In function `SystemClock_Config':
/Users/linjinhui/workplace/stm32f401re/0_blinking/Src/main.c:113: multiple definition of `SystemClock_Config'
build/main.o:/Users/linjinhui/workplace/stm32f401re/0_blinking/Src/main.c:113: first defined here
build/main.o: In function `main':
/Users/linjinhui/workplace/stm32f401re/0_blinking/Src/main.c:68: multiple definition of `main'
build/main.o:/Users/linjinhui/workplace/stm32f401re/0_blinking/Src/main.c:68: first defined here
build/stm32f4xx_it.o: In function `SysTick_Handler':
/Users/linjinhui/workplace/stm32f401re/0_blinking/Src/stm32f4xx_it.c:52: multiple definition of `SysTick_Handler'
build/stm32f4xx_it.o:/Users/linjinhui/workplace/stm32f401re/0_blinking/Src/stm32f4xx_it.c:52: first defined here
collect2: error: ld returned 1 exit status
make: *** [build/0_blinking.elf] Error 1
修复二:去除C_SOURCES中重复的源文件(注:去除后面那个多出来的,具体是stm32f4xx_it.c,stm32f4xx_hal_msp.c,main.c),修改完如下
######################################
# source
######################################
# C sources
C_SOURCES = \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c \
Src/stm32f4xx_it.c \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c \
Src/stm32f4xx_hal_msp.c \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c \
Src/main.c \
Src/system_stm32f4xx.c \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c \
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c
再次make,成功在build子目录下编译出文件显示如下:
➜ 0_blinking make
/usr/local/bin//arm-none-eabi-gcc -c -mcpu=cortex-m4 -mthumb -mfpu=fpv4-sp-d16 -mfloat-abi=hard -DUSE_HAL_DRIVER -DSTM32F401xE -IInc -IDrivers/STM32F4xx_HAL_Driver/Inc -IDrivers/STM32F4xx_HAL_Driver/Inc/Legacy -IDrivers/CMSIS/Device/ST/STM32F4xx/Include -IDrivers/CMSIS/Include -Og -Wall -fdata-sections -ffunction-sections -g -gdwarf-2 -MMD -MP -MF"build/stm32f4xx_hal_gpio.d" -MT"build/stm32f4xx_hal_gpio.d" -Wa,-a,-ad,-alms=build/stm32f4xx_hal_gpio.lst Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c -o build/stm32f4xx_hal_gpio.o
.............
/usr/local/bin//arm-none-eabi-size build/0_blinking.elf
text data bss dec hex filename
4280 12 1572 5864 16e8 build/0_blinking.elf
/usr/local/bin//arm-none-eabi-objcopy -O ihex build/0_blinking.elf build/0_blinking.hex
/usr/local/bin//arm-none-eabi-objcopy -O binary -S build/0_blinking.elf build/0_blinking.bin
用st-flash下载跑马灯:
➜ 0_blinking st-flash write ./build/0_blinking.bin 0x8000000
st-flash 1.4.0
2018-01-07T22:49:52 INFO src/common.c: Loading device parameters....
2018-01-07T22:49:52 INFO src/common.c: Device connected is: F4 device (Dynamic Efficency), id 0x10006433
2018-01-07T22:49:52 INFO src/common.c: SRAM size: 0x18000 bytes (96 KiB), Flash: 0x80000 bytes (512 KiB) in pages of 16384 bytes
2018-01-07T22:49:52 INFO src/common.c: Attempting to write 4204 (0x106c) bytes to stm32 address: 134217728 (0x8000000)
Flash page at addr: 0x08000000 erased
2018-01-07T22:49:52 INFO src/common.c: Finished erasing 1 pages of 16384 (0x4000) bytes
2018-01-07T22:49:52 INFO src/common.c: Starting Flash write for F2/F4/L4
2018-01-07T22:49:52 INFO src/flash_loader.c: Successfully loaded flash loader in sram
enabling 32-bit flash writes
size: 4204
2018-01-07T22:49:52 INFO src/common.c: Starting verification of write complete
2018-01-07T22:49:52 INFO src/common.c: Flash written and verified! jolly good!
哦,没反应,忘了翻转了,还有,另外不要忘了跳冒要接好,,,
修改main函数中while(1),翻转起来:
/* Infinite loop */
/* USER CODE BEGIN WHILE */
while (1)
{
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
HAL_GPIO_WritePin(LD2_GPIO_Port, LD2_Pin, GPIO_PIN_RESET);
HAL_Delay(500);
HAL_GPIO_WritePin(LD2_GPIO_Port, LD2_Pin, GPIO_PIN_SET);
HAL_Delay(500);
}
再次编译和下载,闪起来了,,,
CLion+OpenOCD5.1 安装 OpenOCD:brew install openocd
➜ ~ brew install openocd --enable_ft2232_libftdi --enable_stlink
Updating Homebrew...
==> Auto-updated Homebrew!
Updated 4 taps (caskroom/cask, caskroom/versions, homebrew/core, homebrew/science).
==> New Formulae
opencascade
Warning: open-ocd: this formula has no --enable_ft2232_libftdi option so it will be ignored!
Warning: open-ocd: this formula has no --enable_stlink option so it will be ignored!
==> Downloading https://homebrew.bintray.com/bottles/open-ocd-0.10.0.el_capitan.bottle.1.tar.gz
######################################################################## 100.0%
==> Pouring open-ocd-0.10.0.el_capitan.bottle.1.tar.gz
/usr/local/Cellar/open-ocd/0.10.0: 632 files, 4.7MB
➜ ~ which openocd
/usr/local/bin/openocd
➜ ~ openocd
Open On-Chip Debugger 0.10.0
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
embedded:startup.tcl:60: Error: Can't find openocd.cfg
in procedure 'script'
at file "embedded:startup.tcl", line 60
Error: Debug Adapter has to be specified, see "interface" command
embedded:startup.tcl:60: Error:
in procedure 'script'
at file "embedded:startup.tcl", line 60
5.2 CLion 及其插件
如果要Debug,则需要重新用Cube生成SW4STM32,如下:

安装 CLion 及其插件clion-embedded-arm后,导入刚才 Cube 生成的工程:


CLion 会自动生成 CMakeLists.txt:

用插件生成CMakeLists.txt来替换原来的CMakeLists.txt:


此时,选择Run->Build显示编译成功如下:

配置 OpenOCD 如下:

注:
然后,就可以愉快的 Debug 在线仿真了,,,

作者:Mintisan
链接:https://www.jianshu.com/p/ed7203324ac6
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在本文将会介绍平衡自行车的具体制作过程,包括机械、电路和代码。
平衡自行车完整的代码托管在 https://github.com/nicekwell/balance_bike。

机械
| 名称 | 数量 | 备注 |
|---|---|---|
| 铜柱、铁丝、胶枪等基础材料和工具 | ||
| 自行车架 | 1 | 自己做车架是很麻烦的,我是直接买的车架,淘宝上搜”自行车 拼装 DIY”能搜到很多 |
| 舵机 | 1 | 转向用的,对于我用的1:6车架,普通舵机有点大,我用的是9g舵机 |
| N20电机 | 1 | 选扭力大一点,这样转速会比较稳定 |
| 皮带轮和皮带 | 如上面的图片,我是用皮带来传输动力的 |
电路
| 名称 | 数量 | 备注 |
|---|---|---|
| 电池、电池盒 | ||
| 洞洞板 | ||
| lm1117-3.3 | 降压芯片给控制系统供电 | |
| stm32f103c8t6核心板 | 1 | |
| gy521模块 | 1 | 加速度传感器 + 陀螺仪 |
| 升压模块 | 1 | 升到12v给电机供电,根据电机特性选择是否使用升压模块 |
| 8050三极管 | 2 | 驱动电机,由于自行车不需要反转,所以不需要使用电机驱动芯片,用三极管就能方便地实现。我用了两个三极管并联提高功率。 |
| 自锁开关 | 1 | 整个系统开关 |
| led指示灯 | 1 | 配合1k限流电阻 |
| 蓝牙模块 | 1 | 可选,如果想要遥控的话就使用蓝牙 |
如图,我用的是皮带传送的方式,因为比较好实现。

这个DIY是不考虑变速情况的,平衡的参数都是按照一个固定速度调的。
所以动力部分的作用就是提供一个恒定的速度,并且这个速度尽可能稳定,尽可能不受外部影响。
电机应选择扭力大一些、转速稳定的减速电机。
电机是直接供电还是使用升压模块供电要根据电机特性,有些电机用升压模块可以提高功率,有些大电流电机用升压模块反而可能限制了电流。
我这里用升压模块升到12v给N20电机供电的。

另外,电机通过三极管受stm32控制,通过控制占空比也可以限制电机输出的功率。
转向部分用一个舵机带动把手转动即可。

在github工程里有详细的引脚连接表 https://github.com/nicekwell/balance_bike。
用3.3v稳压芯片给整个控制系统供电,包括单片机、GY521模块、蓝牙模块。
用5v稳压芯片给舵机供电。
用12v升压模块给电机供电。
我是用串口给stm32下载程序的。
| 引脚 | 功能 | 备注 |
|---|---|---|
| PA9 | 下载TXD | |
| PA10 | 下载RXD |
这个模块通过i2c通信,只需要连接4根线。
| 引脚 | 功能 | 备注 |
|---|---|---|
| 3.3v | ||
| GND | ||
| PB0 | GY521 I2C SCL | |
| PB1 | GY521 I2C SDA | 用的是IO模拟i2c |
点击用12v升压模块供电,由于不需要反转,用三极管即可直接驱动,电路图如下:
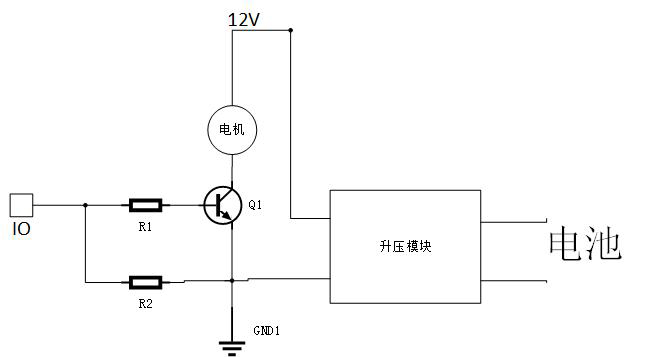
加三极管的目的是为了可以通过调节PWM占空比来限制输出功率,但我的实际情况是100%输出时动力才勉强足够。所以如果你不需要限制电机输出功率,或者通过其他方式限制输出功率,也可以不要三极管,不通过单片机控制。
舵机是用5v供电的,而单片机是3.3v电平,对于pwm控制脚可以通过2个三极管实现同相的电平转换:
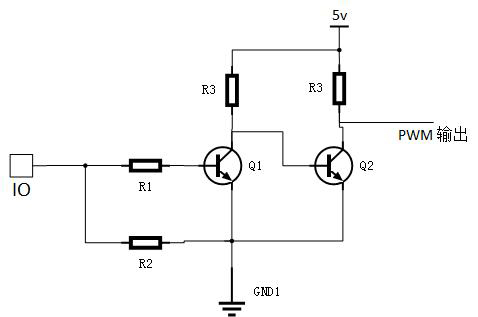
下图是我使用的蓝牙串口模块,可以实现串口透传,只需要4根线连接:vcc、gnd、txd、rxd。

蓝牙模块是用来调试和遥控的,没有它也能跑。建议还是加上这个模块,在调试PID擦数时会非常方便。
关于调试方面的内容可以参考我写的另一片文章:谈一谈单片机开发的几种调试方案
代码提交在github https://github.com/nicekwell/balance_bike。
主要分为3个部分:1、基础的驱动程序,实现电机、舵机、gy521数据读取;2、平衡控制系统,核心是一个20ms定时器,每20ms进行一次数据采集、计算和响应;3、遥控和调试系统,实现log输出、接收遥控信息。
| 名称 | 文件 | 功能 |
|---|---|---|
| i2c | i2c/i2c.c, include/i2c.h | IO 模拟i2c驱动,提供i2c基础操作 |
| gy521 | gy521/gy521.c, include/gy521.h | gy521模块驱动,基于i2c驱动,提供加速度和角速度的读取接口 |
| motor | motor/motor.c, include/motor.h | 电机驱动,提供占空比控制接口 |
| angle | angle/angle.c, include/angle.h | 舵机驱动,提供角度控制接口 |
main函数会初始化一个定时器20ms中断一次,调用 main/balance.c 里的 balance_tick 函数,平衡算法在 main/balance.c 实现。
每20ms到来会执行一次:
两部分:状态输出和指令接收。
状态输出
在main函数的while循环里,利用串口中断构建一个简单的界面显示状态。
指令接收
串口接收到的数据会传给main/control.c,该文件分析串口数据,解释成相应的操作。主要是PID参数调节。
这是平衡自行车三篇教程中的第二篇,这一篇对平衡自行车的算法进行理论分析,包括模型分析、姿态检测方法、PID算法,控制算法。
很显然我们知道自行车在左右方向上不稳定,这是一个很常见的物理模型——倒立摆。

顾名思义,倒立摆的意思就是倒着的摆,比如一个倒着的杆,
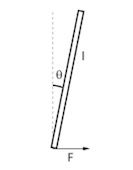
倒立摆的特性:不稳定,只要偏离平衡位置,就会有一个力(重力的分力)使系统更加偏离平衡位置,这样偏差就会越来越大。
一般倒立的杆在前后左右方向都有可能倒下,在二维的平面上不稳定;而自行车仅在左右方向上可能倒下,是一维的倒立摆,这要简单一些。
以下是几个生活中常见的倒立摆例子:



自行车属于倒立摆模型,倒立摆是不稳定的,那么倒立摆应该如何控制才能平衡呢?
我们把问题拆分一下:
我们要对”平衡”进行数学描述,所谓的平衡其实就是倒立摆的倾角稳定在一个我们想要的值。
通常我们想要平衡在θ = 0处。
对于倒立摆模型,通常我们能控制的是底端的 力 或 速度 或 位置,不同的控制量对应的控制方法不同。
对于自行车来说,它的控制方式不像通常的倒立摆那样直接控制底部,而是间接地通过转向来控制,当自行车以一个固定的速度前进时,自行车把手以一定角度进行转向(设为α),自行车会做相应半径的圆周运动,产生相应大小的”离心力”。
在自行车这个费惯性系里看来,只要对把手进行一定角度的转向(α),就会产生一个相应大小的横向力:
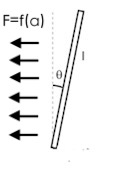
这就是我们进行平衡控制时的实际控制量——把手转角α,只要控制它就能控制回复力。
上面我们已经能够通过转向产生回复力,这个回复力可以把倒立摆”掰回”平衡位置,有往回掰的回复力就能稳定平衡了吗?
并不是这样,我们再来回顾一下中学物理:
过阻尼状态的摆会以较慢的速度回到平衡位置;
欠阻尼状态的摆会很快回到平衡位置,但会在平衡位置来回摆动;
临界阻尼状态的摆会以最快的速度稳定在平衡位置。
结合到实际的自行车平衡中就是:
如果回复力不够大,就无法矫正,或者矫正速度很慢,这会导致系统不稳定;
如果回复力过大,就会导致矫正过度,这也会导致系统不稳定; 我们最希望的状态就是回复力刚刚好,刚好使倒立摆快速回到平衡位置,又不至于矫正过度。
这是一个复杂的数学计算过程,回复力大小会在系统运行时不断地计算(本平衡自行车是20ms计算一次),用到的是PID算法,会在后面详细介绍。
这将会在下面详细讨论。
检测的是自行车左右倾斜的角度。
用一个叫gy521的模块,里面用的是mpu6050芯片,带有陀螺仪和加速度传感器。 gy521的具体使用会在第三篇-实践篇介绍,这里我们知道通过这个模块我们可以得到自行车各个方向的加速度和角速度。 注意哦,我们不能直接得到倾斜角度,我们的到的是各个方向的加速度和角速度,需要进行一些复杂的计算才能得到正确的倾斜角度。
常用的算法有互补平衡滤波、卡尔曼滤波,由于篇幅和精力问题这部分暂不介绍,网上有大量资源,也可以查看本工程源码,以后有时间再写详细教程。
前面已经分析了,我们通过控制把手转角来控制回复力,我们需要实时计算一个合适的回复力使系统稳定平衡。
这部分内容也不做详细介绍了,网上有大量资源,也可以查看本工程源码。
在这里引用动力老男孩举的一个例子,帮大家简单理解一下需要解决的问题,以及PID算法是如何解决的。
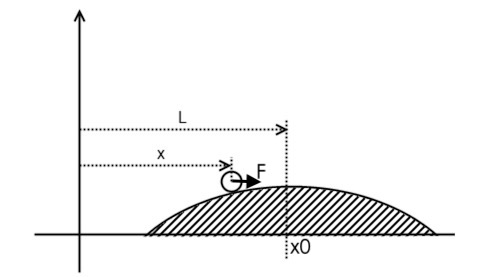
有一个小球在光滑球面上,小球的位置是x,光滑球面顶端在L处,我们可以控制小球水平方向力F,现在要求让小球稳定平衡在x0处。
先看简单情况 x0=L,此时偏差为 L-x,
我们给出一个比例项(P) F = kp*(L-x),这样就会有一个回复力,当偏差存在时就会有一个力把小球拉回L处。
这存在的问题是,小球接近L时是会有一定速度的,小球越来越接近L,此时的力仍然是在把小球往L处拉,这会导致小球到达L时(我们想要的位置)速度很大,小球无法立刻停下来,而是会冲过去。
这样小球就会在L附近来回摆动,这是不稳定的状态,属于欠阻尼状态。
为了解决上述问题需要加一个微分项(D) F = kd*dx/dt = kd*v,所谓”微分”指的是位置x对时间的微分,说白了就是速度。
意思就是当速度越大,就产生一个反向的力使速度减小,这样就可以防止出现上面小球冲过去的。
可以认为这一项具有”预测”功能,预测小球下一时刻的状态从而提前做出反应(预测小球将要到达L处,提前减速),
也可以认为这一项具有阻尼作用,相当于系统中有一个和速度成比例的阻尼力。
这个”阻尼力”调得过小会导致欠阻尼状态,调得过大会导致过阻尼状态。
积分项此时可以不用,积分项是当平衡位置x0不等于L时使用的,
当平衡位置不是L处,那么当小球静止在平衡位置x0时,由于在坡道上会有一个恒定的横向偏移力,此时比例调节作用为0(Δx=0),微分调节作用也是0(v=0),所以小球在该处无法平衡,会在更远离平衡位置处达到平衡,那么就会有一个长时间存在的偏差。
积分作用就是检测偏差进行累积,对于上面这个长时间存在的偏差进行积分(累积叠加),使系统在长时间范围可以稳定在要求的平衡位置。
MIT RACECAR,最早开始做racecar的,主要基于双目摄像头+激光雷达: http://fast.scripts.mit.edu/racecar/hardware/
UPENN F1 TENTH,同MIT racecar特别像,不过很多东西需自己组装,电调模块需自己焊接: http://f1tenth.org/
Daniel Tobias’ CAR – Cherry Autonomous Racecar,基于普通摄像头,利用深度学习来做的
Jetsonhacks Racecar,仿照MIT racecar: http://www.jetsonhacks.com/category/robotics/jetson-racecar/
台湾仿照MIT-RACECAR做的低成本的hypha-racecar
伯克利大学做的不需要激光雷达的racecar
http://www.barc-project.com/setup/
try the following configuration:
https://github.com/francisc0garcia/autonomous_bicycle
继续来深入探讨!在之前的文章(第一部分)中,我们为本篇文章建立了一个上下文环境(以便于讨论)。一个基本原则是,当微服务被引入到现有架构中时,不能也不应该破坏当前的请求流程(request flows)。“单体应用(monolish)”程序依然能带来很多商业价值(因此仍将在新的时代被使用,编者注),我们只能在迭代和扩展时,尽可能地减少其负面影响,这过程中就有一个经常被忽略的事实:当我们开始探索如何从单体应用过渡到微服务时,会遇到一些我们不愿意碰到的难题,但显然我们不能视而不见。如果你还没读过这段内容,我建议你再回去看看第一部分。同时也可以参考什么时候不要做微服务[0]。
关注推特上的(@christianposta)或访问http://blog.christianposta.com,以获取最新更新和讨论。
在此前的第一部分,想解决的问题有:
一、技术层面
以下这些技术在我们的实践过程中将具备一定的指导作用:
• 开发人员服务框架(Spring Boot [1],WildFly [2],WildFly Swarm [3])
• API设计(APICur.io [4])
• 数据框架(Spring Boot Teiid [5],Debezium.io [6])
• 集成工具(Apache Camel [7])
• Service Mesh(Istio Service Mesh [8])
• 数据库迁移工具(Liquibase [9])
• 灰度上线/特性标记框架(FF4J [10])
• 部署/CI-CD平台(Kubernetes [11]/OpenShift [12])
• Kubernetes开发工具(Fabric8.io [13])
• 测试工具(Arquillian [14],Pact [15]/Arquillian Algeron [16],Hoverfly [17],Spring-Boot Test [18],RestAssured [19],Arquillian Cube [20])
我使用的是http://developers.redhat.com上的TicketMonster教程,显示从单体应用到微服务的演变,如果感兴趣的话可以关注,你还可以在github上找到相关的代码和文档(文档还在编写中):https://github.com/ticket-monster-msa/monolith
让我们一步步地读完第一部分 [21],具体来看看每一步应该怎么实施。中间还会引入上一部分中出现的一些注意事项,并在当前背景下再讨论一遍。
二、了解单体式应用

回顾下注意事项:
可以的话,尽可能为单体应用安排大量的测试,哪怕不是一直有效。随着演变的开始,无论是添加新功能还是替换现有功能,我们都需要清楚了解任何更改可能产生的影响。Michael Feathers 在他《重构遗留代码》[22]的书中,将“遗留代码(legacy code)”定义为没有被测试所覆盖的代码。像JUnit和Arquillian这样的工具就很能帮到大忙。使用Arquillian,可以任意选择远程方法调用的接口的颗粒大小(fine grain or coarse grain),然后打包应用程序,不过仍需要用适当的模拟等方式,来运行打算被测试的一部分程序。例如,在单体应用(TicketMonster)中,我们可以定义一个微部署(micro-deployment),用来将原有的数据库替换为内存数据库,并预加载一些样例数据。Arquillian适用于Spring Boot应用、Java EE等。在本例中,我们将测试一个Java EE的单体架构:
public static WebArchive deployment() { return ShrinkWrap .create(WebArchive.class, "test.war") .addPackage(Resources.class.getPackage()) .addAsResource("META-INF/test-persistence.xml", "META-INF/persistence.xml") .addAsResource("import.sql") .addAsWebInfResource(EmptyAsset.INSTANCE, "beans.xml") // Deploy our test datasource .addAsWebInfResource("test-ds.xml"); }
更有意思的是,嵌入在运行环境中的测试可以用来验证内部工作的所有组件。例如,在上面的一个测试中,我们可以将BookingService注入到测试中,并直接运行:
@RunWith(Arquillian.class) public class BookingServiceTest { @Deployment public static WebArchive deployment() { return RESTDeployment.deployment(); } @Inject private BookingService bookingService; @Inject private ShowService showService; @Test @InSequence(1) public void testCreateBookings() { BookingRequest br = createBookingRequest(1l, 0, new int[]{4, 1}, new int[]{1,1}, new int[]{3,1}); bookingService.createBooking(br); BookingRequest br2 = createBookingRequest(2l, 1, new int[]{6,1}, new int[]{8,2}, new int[]{10,2}); bookingService.createBooking(br2); BookingRequest br3 = createBookingRequest(3l, 0, new int[]{4,1}, new int[]{2,1}); bookingService.createBooking(br3); }
完整的示例请参阅TicketMonster单体应用模块[23]中的BookingServiceTest。
测试的问题解决了,那么部署呢?
Kubernetes已成为容器化服务或应用程序的实际部署平台。Kubernetes处理诸如健康度检查、扩展、重启、负载平衡等事项。对于Java开发人员来说,像fabric8-maven-plugin[24]这样的工具甚至都可以用来自动构建容器或docker镜像,并生成任意部署资源文件。OpenShift[25]是Red Hat的Kubernetes的产品化版本,其中增加了开发人员的功能,包括CI/CD pipelines等。

无论是微服务、单体应用还是其他平台(比如能够处理持续的工作负载,即数据库等),Kubernetes/OpenShift都是一个适用于应用程序/服务的部署平台。通过Arquillian,容器和OpenShift pipelines,可以持续地将变更引入生产环境。顺便来看一下openshift.io[26],它将开发经验与自动CI/CD pipelines、SCM集成、Eclipse Che[27]开发人员工作区、库扫描等结合在一起。
目前,生产负载指向单体应用。如果我们翻到它的主页,我们会看到这样的内容:

接下来,让我们开始做一些改变…
三、提取用户界面UI

回顾下注意事项:
如果我们看下TicketMonster UI v1 [29]代码,就会发现它非常简单。静态HTML/JS/CSS组件已经被移到它自己的Web服务器,还被打包到一个容器中。通过这种方式,我们可以在单体应用之外对它进行单独部署,并独立更改或更新版本。这个UI项目仍然需要与单体应用对话来执行它的功能,所以应该是公开一个REST接口,让UI可以与之交互。对于一些单体应用来说,这说起来容易做起来难。如果你想从遗留代码中打包出来一个不错的REST API,又遇到了挑战,我强烈推荐你看看Apache Camel,尤其是它的REST DSL。
比较有意思的是,实际上单体应用并没有被改变。它的代码没有变动,同时新UI也部署完成。如果查看Kubernetes,我们会看到两个单独的部署对象和两个单独的pod:一个用于单体架构,另一个用于UI。


即使tm-ui-v1用户界面部署完了,也没有任何流量进入这个新的TicketMonster UI组件。为了简单起见,即使这个部署并没有承载生产流量,而是ticket-monster这个单体应用在承担所有流量,我们仍然可以把它当作一个简单的灰度上线。相关的UI端口仍旧可以访问:

接下来,用kubectl cli 工具从本地端口转发到特定的pod(端口80上的tm-ui-v1-3105082891-gh31x),并将其映射到本地端口8080。现在,如果导航到http://localhost:8080,应该得到一个新版本UI(注意突出显示的文本部分,表明这是一个不同的UI,但它直接指向单体应用)

如果我们这个新版本还算满意,就可以开始将流量引入进来。为此,我们将使用Istio service mesh [30]。Istio是用于管理由入口点和服务代理组成的网格控制层(control plane)。我已经写了一些关于像Envoy这样的数据层[31]以及service mesh[32]的文章。我个人强烈建议看看Istio的全部功能。接下来的几段内容,我们会围绕整个项目的全过程来依次展开讨论Istio的各项功能。如果控制层和数据层之间的区分让你困惑,请查看Matt Klein[33]撰写的博客。
我们将从使用Istio Ingress Controller[34]开始。该组件允许使用Kubernetes Ingress规范来控制流量进入Kubernetes集群。一旦安装了Istio,我们可以这样创建一个入口资源,将流量指向Ticket Monster UI的Kubernetes服务,tm-ui:
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: tm-gateway annotations: kubernetes.io/ingress.class: "istio" spec: backend: serviceName: tm-ui servicePort: 80

一旦有了入口,就可以开始应用Istio路由规则[35]。例如,有一个规则,“任何时候有人试图与在Kubernetes中运行的tm-ui服务对话,将它们指向服务的第一版本v1”:
apiVersion: config.istio.io/v1alpha2 kind: RouteRule metadata: name: tm-ui-default spec: destination: name: tm-ui precedence: 1 route: - labels: version: v1
如此,我们能够更好地控制进入集群甚至深入集群内部的流量。在这个步骤的最后,我们会将所有的流量都转到tm-ui-v1部署。
四、从单体架构移除UI

回顾下注意事项
这一步相当直接,通过删除静态UI组件来更新单体应用(删除的部分已经转移到了tm-ui-v1部署)。既然应用程序已经被释放成为一个单体应用的服务,以供UI,API或者其他一些程序调用,那么也可以对这个部署进行一些API层级的更改。而如果想对API进行一些更改,就需要部署一个新版本的UI。此处我们部署了backend-v1服务以及一个新的UI tm-ui-v2,可以利用后端服务中的这个新API。
来看看在Kubernetes集群中的部署情况:

此时,ticket-monster和tm-ui-v1正接收实时流量。backend-v1和指向它的UI–tm-ui-v2则没有流量负载。需要注意的一点是,backend-v1部署与ticket-monster部署共享数据库,但各自有略微不同的外向API(outward facing API)。
现在,新的backend-v1和tm-ui-v2组件已经部署到生产环境中。现在是时候把注意力放在一个简单而又重要的事实上:生产环境部署发生了改变,但是它们还没有发布。在turblabs.io [36]一些优秀的博客更详细地阐述了这一点[37]。现在,我们有机会部署一个非正式的灰度发布。也许我们希望这个部署慢慢来,首先面向内部用户,或者先对某个特定区域内,特定设备的部分用户进行部署等等。

既然已经有了Istio,接下来看看它能做些什么。我们只想为内部用户做一个灰度发布。我们可以用各种方式来识别内部用户,诸如headers、IP等等,在本例中,如果HTTP header带有 x-dark-launch: v2 这样的文本内容,则该请求将会被路由到新的backend-v1和tm -ui-v2服务中。以下是istio路由规则的样子:
apiVersion: config.istio.io/v1alpha2 kind: RouteRule metadata: name: tm-ui-v2-dark-launch spec: destination: name: tm-ui precedence: 10 match: request: headers: x-dark-launch: exact: "v2" route: - labels: version: v2
任意用户身份登录主页时,应该可以看到当前的部署(即指向ticket-monster单体应用的tm-ui-v1):
现在,如果改变浏览器中的消息头(例如使用Firefox的修改消息头工具或其他类似工具),我们应该被路由到已灰度上线的服务(指向backend-v1的tm-ui-v2):

然后点击“开始”开始修改消息头并刷新页面:

现在,我们已经被重定向到服务的灰度发布版本。由此,可以通过做一个金丝雀发布(这里也许引1%的实时流量到新部署),来向客户群发布,同时,如果没有负面效果的话,那么就缓慢增加流量负载(5%、10%、50%等)。以下是Istio路由规则的一个例子,其将v2流量以1%进行金丝雀发布:
apiVersion: config.istio.io/v1alpha2 kind: RouteRule metadata: name: tm-ui-v2-1pct-canary spec: destination: name: tm-ui precedence: 20 route: - labels: version: v1 weight: 99 - labels: version: v2 weight: 1
能“看到”或“观察”这个版本的影响是至关重要的,稍后我们会进一步讨论。另外请注意,这种金丝雀发布方式目前正在架构外围完成,但是也可以通过istio控制内部服务间通讯/交互时采用金丝雀的方式。在接下来的几个步骤中,我们将开始看到。

五、引入新服务

回顾下注意事项
在这一步中,我们开始设计我们所设想的新订单服务的API,在做一些领域驱动设计练习时,我们常常需要确定一些边界(boundaries),新的API应该更多的与这种边界相一致。这里可以使用API建模工具来设计API,部署一个虚拟化的实施,并且随服务消费者的需求变化 一起迭代,而不是一开始花费大量的精力去构建,最后又发现需要不断修改。
在TicketMonster重构时,需要在单体应用中保留一个上文所说的API,以便在最初的服务拆分时尽可能轻松并且降低风险。无论是哪种情况,有两个给力的工具可以帮到我们:一个是网页式的API设计器,apicur.io[38],一个是测试/ API虚拟化工具,Hoverfly[39]。Hoverlfy是模拟API或捕获现有API流量的好工具,可以用来模拟mock端点。
如果我们正在构建一个新的API,或在使用领域驱动设计方法后,想看看API什么样,可以使用apicur.io工具建立一个Swagger/Open API的规范。

在TicketMonster这个例子中,我们通过在代理模式下启动hoverfly,并使用hoverfly捕获从应用程序到后端服务的流量。我们可以在浏览器设置中设置HTTP代理,从而通过hoverfly发送所有流量。这将把每个请求/响应对(request/response pair)的仿真存储在JSON文件中。这样我们就可以在Mock里使用这些请求/响应对,或者更进一步,用它们开始编写测试,以规范具体的实现代码中的一些行为。
对于所关注的请求或响应对(response pairs),我们可以生成一个JSON架构并用于测试中,参见https://jsonschema.net/#/editor。
例如,结合使用Rest Assured和Hoverfly,可以调用hoverfly模拟,并确定该响应符合我们预期的JSON架构:
@Test public void testRestEventsSimulation(){ get("/rest/events").then().assertThat().body(matchesJsonSchemaInClasspath("json-schema/rest-events.json")); }
在新的订单服务中,可以查看HoverflyTest.java [40]测试。有关测试Java微服务的更多信息,请查阅Manning这本给力的书,《测试Java微服务》[41],我的一些同事Alex Soto Bueno[42]、Jason Porter[43]和Andy Gumbrecht[44]也参与了这本书的撰写。
由于这篇博文已经很长了,我决定将最后的部分单独写成本主题的第三部分,其中将涉及在单体应用和微服务之间管理数据、服务消费的契约测试(consumer contract testing), 功能发布控制( feature flagging),甚至更复杂的istio路由等内容。本系列的第四部分将展示一个包含上述内容的实操Demo,使用负载仿真测试(load simulation tests)和故障注入(fault injections)。欢迎访问我的网站 [45]和关注我的Twitter [46]。
原文链接:http://blog.christianposta.com/microservices/low-risk-monolith-to-microservice-evolution-part-ii/
参考地址:
[0] http://blog.christianposta.com/microservices/when-not-to-do-microservices/
[1] https://projects.spring.io/spring-boot/
[2] http://wildfly.org/
[3] http://wildfly-swarm.io/
[4] http://www.apicur.io/
[5] https://github.com/teiid/teiid-spring-boot
[6] http://debezium.io/
[7] http://camel.apache.org/
[8] https://istio.io/
[9] http://www.liquibase.org/
[10] https://ff4j.org/
[11] https://kubernetes.io/
[12] https://www.openshift.org/
[13] https://fabric8.io/
[14] http://arquillian.org/
[15] https://github.com/pact-foundation/pact-specification
[16] http://arquillian.org/arquillian-algeron/
[17] https://hoverfly.io/
[18] https://docs.spring.io/spring-boot/docs/current/reference/html/boot-features-testing.html
[19] http://rest-assured.io/
[20] http://arquillian.org/arquillian-cube/
[21] http://blog.christianposta.com/microservices/low-risk-monolith-to-microservice-evolution/
[22] https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
[23] https://github.com/ticket-monster-msa/monolith/blob/master/monolith/src/test/java/org/jboss/examples/ticketmonster/test/rest/BookingServiceTest.java
[24] https://maven.fabric8.io/
[25] https://www.openshift.com/
[26] https://openshift.io/
[27] https://www.eclipse.org/che/
[28] http://blog.christianposta.com/deploy/blue-green-deployments-a-b-testing-and-canary-releases/
[29] https://github.com/ticket-monster-msa/monolith/tree/master/tm-ui-v1
[30] https://istio.io/
[31] http://blog.christianposta.com/microservices/00-microservices-patterns-with-envoy-proxy-series/
[32] http://blog.christianposta.com/microservices/application-network-functions-with-esbs-api-management-and-now-service-mesh/
[33] https://medium.com/@mattklein123/service-mesh-data-plane-vs-control-plane-2774e720f7fc
[34] https://istio.io/docs/tasks/traffic-management/ingress.html
[35] https://istio.io/docs/reference/config/traffic-rules/routing-rules.html
[36] https://www.turbinelabs.io/
[37] https://blog.turbinelabs.io/deploy-not-equal-release-part-one-4724bc1e726b
[38] http://www.apicur.io/
[39] https://hoverfly.io/
[40] https://github.com/ticket-monster-msa/monolith/blob/master/orders-service/src/test/java/org/ticketmonster/orders/HoverflyTest.java
[41] https://www.manning.com/books/testing-java-microservices
[42] https://twitter.com/alexsotob
[43] https://twitter.com/lightguardjp
[44] https://twitter.com/andygeede?lang=en
[45] http://blog.christianposta.com/
[46] https://twitter.com/christianposta
GTD 最早于2002年由 David Allen 提出,自他撰写的畅销书 Getting Things Done 出版以来,“GTD” 已经成了一个术语,影响了大批致力于推动时间管理的图书及博客作者、企业管理者,甚至因此诞生了一批基于 GTD 的效率工具。它的内容从不过时,与时代发展同步行进,影响着全球成千上万的效率实践者。
人们之所以对此乐此不疲,是因为 GTD 与[我想掌控自己的生活][我希望得到尊重与回报][我想要的是什么][我希望能着眼未来]关联密切——它并不仅仅解决工作问题,它试图帮人们理顺每一个日常,从全局角度审视人生。就像一个精密的神经系统,从任何角度唤醒神经元,都有对应的触发路径与反馈。

正在谱写乐曲的巴赫,正在向欧洲行军的拿破仑,正在创造艺术品的安迪沃霍尔,他们都需要处理大量信息并转化为自己的行为决策,以此体现自我意志。一个处理纷繁信息并无时无刻不在作出正确决策的人,在今天被称为专业人士。
毫无疑问,从 GTD 中获利最大的是专业人士。这里有一个虚拟形象,或许你见到过与他相似的人——前一晚工作了很长时间,他选择把工作带回家,结束已经是凌晨3点。他感到自己很少有时间去做喜欢的事情,比起这一点,没完成工作会更让他有负罪感。大部分时间他应对自如,但仍然感到重重压力。有些时候,他会把工作拖到最后时刻,再灵感迸发地完成它,每当这时候,他总后悔没有早点进入 aha moment.第二天早起赶到办公室,办公桌上堆积了许多很久没触碰过的文件。处理邮件到一半,同事拿着合同过来打断他,交谈完毕日历正好弹出5分钟后的会议提醒。结束后已经是中午,他和同事们在办公室一起用餐,想到自己上周忘记了一个重要约会。他感到很难让自己停下来,保持忙碌有一种安全感。他的勤勉为自己换来了尊重,在成功又琐碎的氛围中,他无暇着眼未来,他需要 GTD 来管理自己的工作与生活——
“通过行动让自己感觉良好,要比通过让自己感觉良好来实现更好的行动容易得多。”
时间管理四象限法则把事务分为四种优先级:既紧急又重要、重要但不紧急、紧急但不重要、既不紧急也不重要。大部分时候,人们最优先处理第一种事务,把第二种事务作为长线供养,后两种被视为归档事务被忽略。这些事永远客观存在于生活中,人们无法如同精密仪器时刻不逾陈规。GTD 建议把所有事务不计前嫌统归到一起。有时候,正是一些前置的关联事务,让我们真正开始解决问题时毫不费力。另外 GTD 的两分钟法则认为:如果采取某项行动最多需要两分钟,就应该在作出决定的一刹那实施行动,这可以有效解决部分紧急任务。
“提升个人工作效率低最佳手段之一,就是拥有你乐于使用的管理工具。”
养成收集的习惯至关重要,匹配的管理工具能够安放所有收集到的事务。找到一款项目与任务管理工具,梳理所有引起注意的事务和信息。Teambition 的任务管理功能可以有效解决此类问题,在这里,你可以创建任何主题的事务,在下一步,我们将进行进一步归纳整理。
进一步梳理经上一步统计到的所有事务。事务分为两种,一种是没有行动解决方案的,比如一个想法或者一个软件升级提醒,把这类事务安排到未来的日程,在日程下做好附注。另一类需要进一步行动解决方案的事务,比如参加会议、回顾工作或者洗车,设定每一步具体动作的完成时间。有时委派他人代劳也是完成事务的方法,如果你自己不是最佳的执行人选。在 Teambition 中,你可以指派任意任务给最适合完成它的人,无论他是你的同事、合作伙伴、学习搭档还是家庭成员。
到这一步事务开始变得明朗,大部分事务已经在时间线设定好位置。现在需要做的,是根据不同的情境,把事务归属到不同类别的清单。比如,“立即执行”清单,里面都是在2分钟内就能完成的简单任务。“等待”清单,指关注结果不关注过程的事,比如等待预定的电影票、用户对新提议的回复、等待新购买的空气净化器等。“外出事宜”清单,出门前看一看清单,能有效提升一路上能解决事务的数量与效率。Teambition 的自定义任务面板可以随心所欲地设定为不同主题的清单,你只需要在使用时重新打开他们就能一目了然。你有什么关于清单的好主意,请留言或邮件告诉给我们。
将所有任务在进行优先级排期与清单归纳后,进入回顾阶段——查看事务被着手解决的合理性。首先查看日程表,再看一看行动清单,根据情境选择恰当的回顾内容。人们总会放任自己的大脑纠缠于大量超过自身承载能力的任务数量。回顾的优点在于,尽可能冷静地重审自己的计划,重新夺回主动权而不至于疲于奔波。
终于到了执行阶段,根据4种标准确认下一步的行动:情境、时间、精力、以及优先级。优先执行事先安排好的工作,再处理突发事件。有突发事件时,判断它是否值得你停下目前正在进行的工作,一旦被打断工作,重新进入工作状态将付出较高时间成本。实际上,并不存在被打断工作这回事,只是对新事物管理不善。
三个原则的 Getting things done 精髓:
GTD 强调收集、思考并行动的重要性,五个步骤的最后一步才是真正的执行,前四步无一不是在确保事务解决的合理性与可行性。剥离开或关联或疏离的事项,一次只做一件事。
“一次只做一件事,沉浸通常伴随对特定任务的全身心关注,而且你通常会有掌控感,感到目标清晰。处于沉浸状态的个人通常明白接下来会发生什么事情,并能在执行整个任务的过程中得到及时反馈。”——认知科学家 Mihaly Csikszentmihalyi 《沉浸:关于最佳体验的心理学》
初入 GTD 的实践者,随着习惯的养成与方法的熟悉,会逐渐形成一套以自己为中心的地图,包含自己的角色、职责和兴趣,基于个人发展方向和需求而不断迭代,最终形成综合的全面生活管理系统。在任何情况下,用 GTD 的方法辅以匹配的工具,应对不同属性的事务,提升工作与生活效率。
 |
| 在几天之前,大家看完Honda发布的自动平衡技术之后,相信心中都有不少疑问。大家都想知道其运作原理,老手会担心会否影响电单车原有的操控,买家也想知道新技术何时才能应用在市贩型号之上。今次为大家带来好消息,今天Honda进一步发表riding Assist的技术细节,保证人人都会开心满意。 |
| 当车速达到可以平衡车身时,前叉倾角收缩,回复至街车水平。
|
||
|
||
 上图是正常行车状态,头叉角度较直。 下图是慢车或停车状态,头叉较为向外哨出。  |
||
|
||
 |
||
|
||
 试想像一下,座高870mm的CRF1000,当配备Riding Assist之后,身高只有160mm的女骑士,也不用担心落脚的问题。这项发明,将会彻底改变骑士选择机车的方向。 |


